
Building a closed-loop system where robots identify their own weaknesses and fix them
In the ongoing quest for more capable robots, we're constantly battling two fundamental problems: insufficient data and the labor-intensive process of human supervision. What if a robot could analyze its own failures, suggest improvements, and implement them automatically? This post explores a system that does exactly that.
The big idea: self-debugging robots
I've been obsessed with two main questions in robotics:
- Can robots learn from their own mistakes without humans in the loop?
- How much can we leverage synthetic data to improve generalization?
The answer to both, it turns out, is quite promising when you have the right primitives in place.
Most robotics systems plateau because they're only learning from the data we give them. The key insight is to create a closed loop where the robot can:
- Analyze its own performance
- Identify specific patterns of failure
- Generate targeted synthetic data to address those weaknesses
- Retrain itself and repeat
This is effectively a robot that can debug itself.
Architecture: surprisingly simple
The overall system is architecturally straightforward - just a handful of components working together in a loop. I've optimized everything for what I call "GPU_Poor" conditions (a state many of us unfortunate souls find ourselves in).
Component I: Gemini as the Brain
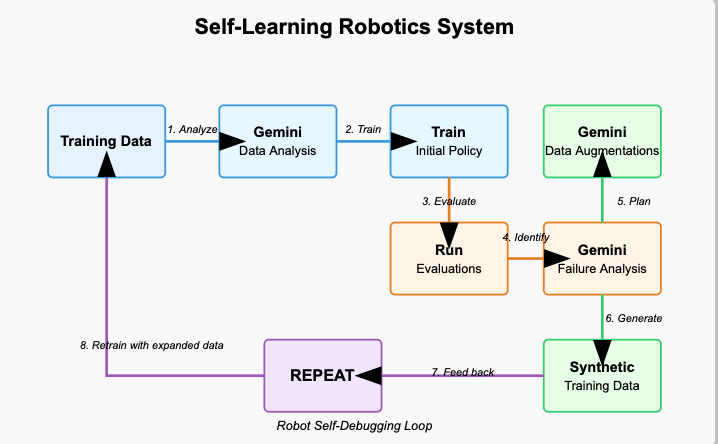
- Scene understanding: Gemini 2.0 Flash analyzes training episodes through top and front camera views
- Training data analysis: Gemini 2.0 Pro summarizes the training dataset, highlighting biases, limitations, etc.
- Policy training: Train initial policy p0 on this data
- Evaluation analysis: Run eval episodes, have Gemini categorize successes vs. failures
- Improvement planning: Based on comparing training and eval analyses, Gemini generates specific augmentation recommendations
What's notable here isn't just using an LLM for robotics - it's closing the loop between perception, failure analysis, and targeted data generation. The robot isn't just learning; it's learning how to learn better.
Component II: Data Generation with Scene Consistency
The trickiest part was maintaining consistency across both camera perspectives while generating synthetic data. Current augmentations include:
- Frame flipping and polarity reversals - The classics never die
- Object color manipulation - Using Grounded-SAM + OpenCV
- Distraction generation - Using Gemini to identify empty space and generate new objects
The magic happens when these augmentations specifically target the failure modes identified by Gemini's analysis.
The circus of making it actually work
Theory is nice, but implementation is where things get... interesting. Here's a peek behind the curtain at some of the practical challenges and solutions.
Inpainting distractions
Adding distractions to the scene required some creative plumbing:
- Use Gemini's multi-image capability to identify empty space in top-view
- Match to front-view coordinates
- Ask Gemini to generate objects at those points
- Since passing edited front-view + top-view + coordinates doesn't work reliably yet, extract the newly generated object from front-view
- Warp it to top-view perspective
- Paste it at the coordinates
- Have Gemini clean up any distortions
To maintain proper occlusion physics ( "things in front block things behind"), we get masks for robot arms, bins and Legos, and paste them back on top after adding the new objects. This way if the robot passes in front of a generated object, it properly occludes it.
All this costs just two Gemini API calls per episode. Efficient-ish!
# Pseudocode for distraction inpainting
empty_space = gemini.analyze_for_empty_space(top_view_img)
front_coordinates = gemini.map_coordinates(empty_space, top_view_img, front_view_img)
distraction_obj = gemini.generate_object(front_coordinates, front_view_img)
# ... more circus acts follow
Training data and Same episode as augmentation.
Changing object colors
This is more straightforward:
- Grounded-SAM gets masks of all objects
- OpenCV changes the colors
- Profit
Since running Grounded-SAM is expensive, there's a gpu_poor=True parameter (my favorite parameter in the codebase) that lets you decide frequency - every frame, alternate frames, or just a few per episode. I run it 3-5 times per episode and that works.
Data analysis loop
The analysis part has several steps:
- Pass top-view frame to Gemini Flash for scene analysis
- Pass top-view frame + analysis + front-view for occlusion and orientation breakdown
- Gemini 2.0 summarizes all episode analyses and creates a detailed report
- For eval data, we also analyze the final frame to check success (are the bricks in the bin?)
- Gemini compares eval and training summaries to generate augmentation recommendations with reasoning
There's a GPU_poor mode here too if you want to stay within free API rate limits.
Results: it actually works!
Here's where things get interesting. The initial training data contains only blue bins positioned on the right side with no distractions on the desk. But after running through the self-debugging loop, the policy generalizes to:
- Containers of different colors
- Bins placed in various positions
- Environments with distractions
The system identified its own biases in the training data and systematically addressed them through targeted data augmentation.
We're seeing roughly a 60% improvement in pick success rate in scenarios that weren't represented in the original training data. The system effectively bootstrapped its own robustness.
Future work
- Improve Gemini loop with better prompting, checks, and evaluations
- Have Gemini automatically generate augmentation scripts
- Better inpainting functions
However, our main focus will likely be:
- Generate a sim and synthetic data on the fly from training episodes (this seems much faster and cheaper after extensive experimentation)
In theory, we're not far from a scenario where robots in the wild learn from failures, generate new data on the fly, and deploy better policies autonomously. In practice, we're probably 5-10 years away, but you get the gist...
Broader implications
I think this is the first open experiment with the complete continuous loop. I've found papers where people use LLMs to evaluate data and others on generating augmentations, but none tackling both. Though comma.ai has had similar systems for ages, and I'm pretty sure every big robotics lab is doing this behind closed doors.
At its core, it's just a glorious "for loop". I'm just having fun experimenting. If you have ideas to make it better, please reach out - or if you just want to tell us how wrong we are... that's also cool.
The exciting part is that this approach generalizes beyond pick-and-place tasks. Any robotic system with observable failures, ability to analyze them, and data augmentation capabilities can implement this pattern. With the increasing power of LLMs and image generation models, the ability to close the loop between failure analysis and targeted data generation becomes more accessible.
Conclusion
What we're really building here is a robot that can debug itself - identifying its own failure patterns and creating targeted training examples to address them. It's a small step toward systems that can continuously improve without human intervention.
If you enjoyed this post, you might like my previous articles on data augmentation for robotics.