
Alright, let's talk about NVIDIA's GR00T N1. In our series on Demystifying robotic Foundation Models, we started with Pi0, which introduces the VLA model architecture with flow matching and pre and post training recipe. GR00T N1 shares some high-level ideas but takes distinct approaches, especially when it comes to data. It heavily leverages simulation, synthetic data generation, and clever ways to use action-less videos.
Let's cover the basics around the model and architecture first, so later on we can delve (see what I did there? 😉) more into the really meaty data augmentation (neural trajectories) part.
GR00T N1: Model & Architecture Basics
Now, GR00T N1 also uses a VLM + action model recipe, incorporating flow matching concepts similar to what we discussed with Pi0. However, NVIDIA made specific adaptations, particularly suited for training with diverse data, including synthetic and latent action labels.
Embodiment-Specific Components: A key feature is the use of embodiment-specific action & state encoders and decoders within its Diffusion Transformer (DiT) action module (which they call System 1). This provides flexibility, allowing the same core model to handle inputs and outputs for different robots (or even human video pseudo-actions) by using these adaptable "adapter" layers. This is crucial for training effectively on their heterogeneous dataset.
VLM & Attention: They use NVIDIA's Eagle-2 VLM as the backbone (System 2). Instead of Pi0's MoE-like structure, GR00T uses standard cross-attention to connect the VLM's output (VLM is not fine-tuned but Frozen) to the DiT action module.
Auxiliary Object Detection Loss: The main training objective is the flow-matching loss (Lfm) for actions, but they add an auxiliary object detection loss (Ldet): L = Lfm + Ldet
Why? The intuition is to force the model's vision system to explicitly locate the key object mentioned in the instruction. This helps ground the actions – the model learns to associate its predicted movements with the relevant object in the scene. It's a neat trick to improve spatial understanding relevant to the task. (Auxiliary losses are pretty common in self-driving & CV in general – I remember Jeremy Howard mentioning something similar for a fish classification task in one of the first FastAI courses, using bounding boxes to help the main task).
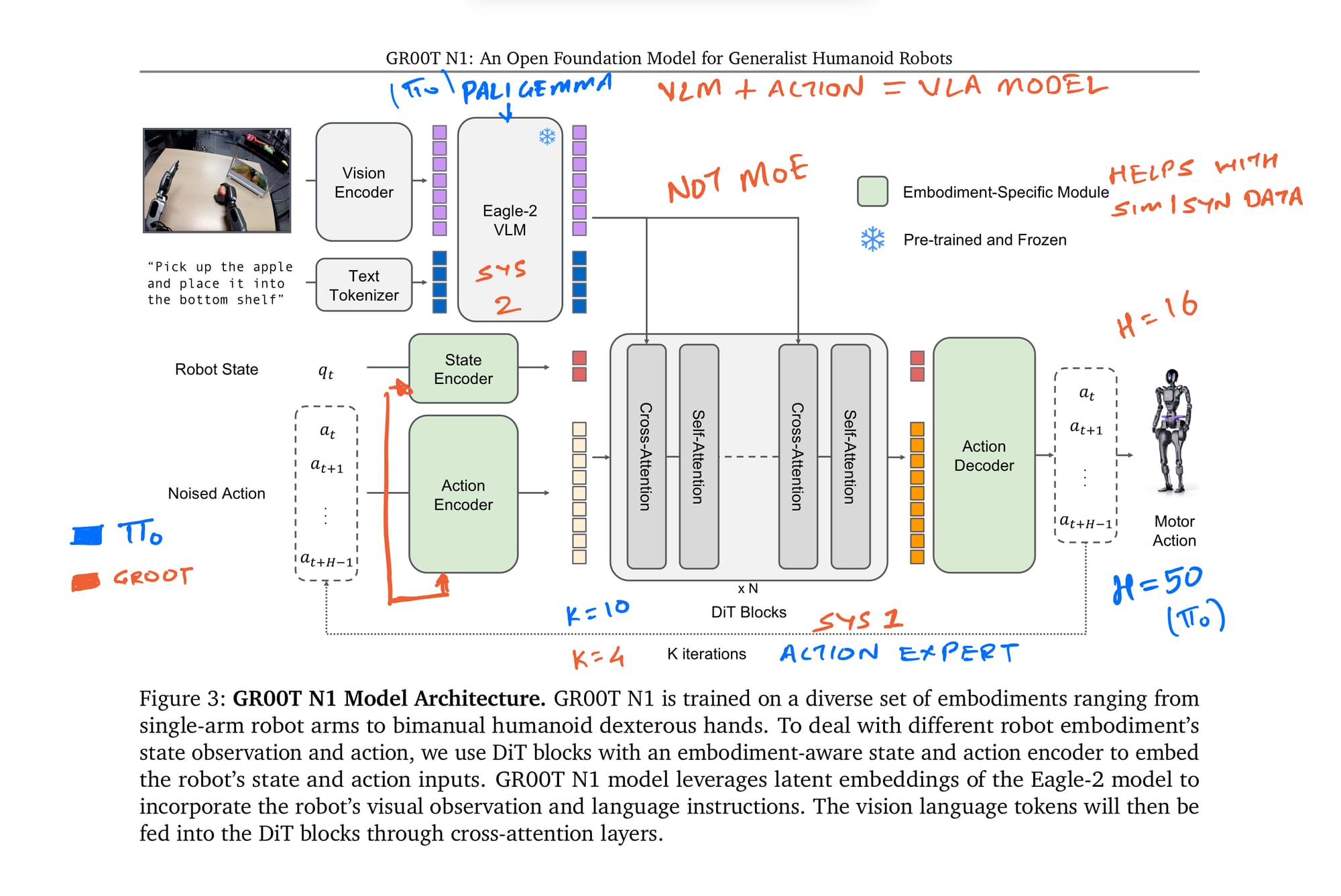
Action Chunking: GR00T N1 uses a shorter action chunk horizon (H=16) compared to Pi0's H=50. Given that Pi0 rarely seemed to execute the full 50 steps before re-planning (often 16 or 25 steps), H=16 might be sufficient for many tasks while being computationally lighter.
Demystifying the Data: Neural Trajectories & Pseudo-Actions
The internet is full of videos with people doing useful things like wet lab work, assembling, cooking etc. However, those videos don't come with action values. Now imagine if you could use those to directly train your robots! This is where GR00T's strategy gets really interesting – how they leverage data without explicit action labels.
I: Latent Actions (The "What-Kind-of-Motion-Was-That?" Embedding)
Okay, so you have a human video – someone picking up a cup. You don't know their exact joint angles. Trying to predict precise robot joint angles from this would be messy, maybe impossible. So, instead of predicting concrete actions, the idea here is to predict an abstract representation of the motion itself.
1. The Setup (VQ-VAE): They train a VQ-VAE. The encoder looks at a frame t and a future frame t+H. Its job is to spit out a vector, an embedding, that captures the "essence" of the movement between those frames. During the VQ-VAE training, there's a codebook involved – a dictionary of learned motion "prototypes" – and a decoder that tries to reconstruct the future frame from the starting frame and the chosen motion prototype code. This helps structure the learned embedding space.
2. Policy Training: When they want to generate pseudo-actions to train the main GROOT N1 policy, they just take the continuous vector straight out of the trained VQ-VAE encoder. This vector becomes the "latent action" label.
3. What it means: This vector isn't joint angles; it's just a point in some learned latent space that implicitly represents "move arm this way" or "grasp like that" based on what the VQ-VAE learned from seeing tons of videos (human, robot, synthetic – they train it on the mix!).
4. Training GR00T: The main GROOT policy then learns, for human video inputs, to predict these latent action vectors. They treat it like a separate "virtual robot embodiment" they call "LAPA". So, it learns general visual patterns and motion intentions without needing explicit human pose data.

II. Augmenting Robot Data (Video Generation + IDM)
If you remember the data pyramid, the least amount of data is the real world robot data. And that is also one of the most crucial elements. Be it Pi0 or Gemini robotics, every foundational model requires robot-specific and task-specific post training. And more the merrier.
GR00T massively augments its 88 hours of real data to ~827 hours using gen-AI!
Step 1: Generate Videos ("Neural Trajectories")
- Fine-tune video generation models on the existing real robot teleop data.
- Use these models to generate new video episodes, often starting from real initial frames but with new text prompts (automated using a VLM) to create diverse scenarios (They mention generating 81-frame videos at 480p – maybe around 8-10 fps for ~10 seconds?). Quality control is done using a VLM judge.
A fine-tuned video makes much more sense, because I couldn't get Sora to generate anything useful.
Sora generated video
Step 2: Generate Action Labels (IDM)
This approach is a bit more direct, especially when the action-less video is closer to the robot's world (like the "neural trajectories" they generate based on real robot data).
1. The Setup: If you have some data where you do know the robot actions (like from teleoperation), you can train a model to predict actions given visual change. This is an Inverse Dynamics Model (IDM), bit similar to imitation learning, you could say. You feed it frame t and frame t+H, and it learns to output the sequence of real robot actions (a_t...a_t+H-1) that happened in between. Nvidia uses a Diffusion Transformer for this IDM, similar to their main action generation module and again with flow matching.
2. Policy Training: Once this IDM is trained, you can point it at videos where you don't have actions (like their generated neural trajectories). You feed it pairs of frames, and the IDM makes an educated guess: "Based on what I saw in the real data, the robot actions between these two frames probably looked like this."
3. Training GR00T: These predicted robot actions are then used as pseudo-action labels for training the main GROOT policy. Again, they might treat this as a slightly different data source or "embodiment" during training.

Why Use Neural Trajectories? (The Advantages)
So why go through the trouble of generating these AI videos ("neural trajectories") instead of just using more physics simulation? There seem to be a couple of key potential advantages:
Closer to Reality Domain: Since these video models are fine-tuned on real robot footage, the generated videos might capture the visual appearance, lighting nuances, and maybe even subtle dynamics of the real world more faithfully than a pure physics simulation. This could potentially reduce the sim-to-real gap the policy needs to cross later.
Handling Complex Physics (Implicitly): Let's face it, simulating things like pouring coffee, watering plants (fluids!), or folding laundry (cloth!) accurately in physics engines is still really hard. Video generation models, trained on countless real-world videos, might implicitly learn how these things look when they happen, potentially generating more visually plausible sequences for these tricky scenarios than current sims can easily achieve, even if the underlying physics aren't perfectly simulated by the video model itself. Pretty neat way to potentially bypass difficult simulation challenges!
The Cost of Data
Generating those 827 hours of neural trajectories took ~105k L40 GPU hours. So yeah, definitely not cheap, but potentially cheaper and quicker than collecting 800+ hours of real robot data!
Don't Forget Simulation
Besides neural trajectories and human videos, GR00T also uses large-scale simulation data generated via systems like DexMimicGen.
Key Takeaways
GR00T N1 showcases NVIDIA's vision for a generalist humanoid model, heavily enabled by diverse data sources. Key takeaways are the dual-system architecture, embodiment-specific adapters, and especially the innovative use of synthetic data (neural trajectories) and pseudo-actions (Latent Actions/IDM) to leverage action-less video at scale. While building on concepts seen in models like Pi0, its data strategy is a major distinguishing feature.
Interested in robotics foundation models? Read our full series starting with Pi0: Demystifying Robotic Foundation Models. Follow our research as we continue exploring the latest developments in AI and robotics. Get in touch if you're working on similar challenges.